引言
随着互联网信息的爆炸式增长,舆情分析系统成为政府、企业和社会组织监测舆论态势、预警潜在风险的关键工具。基于大数据的舆情分析系统架构中,数据处理与存储服务作为核心组成部分,承担着数据采集、清洗、整合与持久化存储的重要职责。本文将从架构角度,深入探讨数据处理及存储服务的设计原则、技术选型及其在舆情分析系统中的作用。
一、数据处理服务的设计与实现
数据处理服务是舆情分析系统的基石,负责从多源异构数据中提取有价值的信息。其架构通常包括以下关键环节:
- 数据采集模块:
- 通过爬虫技术、API接口或日志收集工具,实时或批量抓取来自社交媒体、新闻网站、论坛等渠道的舆情数据。
- 支持多协议接入(如HTTP、Kafka、FTP),并具备去重和增量采集能力,确保数据的全面性和时效性。
- 数据清洗与预处理模块:
- 对原始数据进行噪声过滤、格式标准化、编码转换和实体识别(如人名、地名、机构名)。
- 利用自然语言处理(NLP)技术进行分词、词性标注和情感极性分析,为后续分析奠定基础。
- 数据集成与转换模块:
- 将清洗后的数据转换为统一的格式(如JSON、Avro),并整合至数据流水线。
- 采用流式处理框架(如Apache Flink、Spark Streaming)实现实时数据处理,确保低延迟响应。
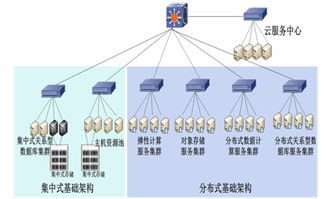
二、数据存储服务的架构设计
数据存储服务需满足海量数据的高效存储、快速查询和可扩展性需求。其设计通常分为实时存储与离线存储两层:
- 实时存储层:
- 使用NoSQL数据库(如Elasticsearch、HBase)存储近实时舆情数据,支持全文检索和复杂查询。
- 结合内存数据库(如Redis)缓存热点数据,提升实时分析和仪表盘展示的性能。
- 离线存储层:
- 基于分布式文件系统(如HDFS)或数据湖(如Delta Lake)存储历史数据,用于深度分析和模型训练。
- 采用列式存储格式(如Parquet、ORC)优化查询效率,并利用数据分区和索引策略加速数据访问。
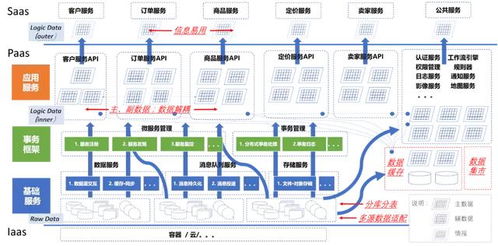
三、关键技术选型与优化策略
在数据处理与存储服务中,技术选型直接影响系统的性能和可靠性:
- 数据处理框架:优先选择支持容错和水平扩展的框架,如Apache Kafka用于数据流传输,Spark用于批量处理。
- 存储引擎:根据数据访问模式选择合适的存储方案,例如Elasticsearch适用于文本搜索,而Hive适合离线分析。
- 数据安全与合规:通过加密传输(TLS/SSL)、访问控制(RBAC)和数据脱敏技术,确保舆情数据的安全性和隐私保护。
四、实践案例与挑战应对
以某政府舆情监控系统为例,其数据处理与存储服务通过以下方式优化:
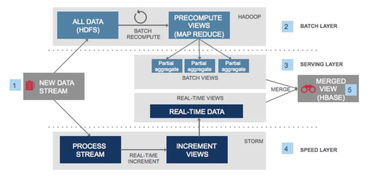
- 采用Lambda架构兼顾实时与批量处理,日均处理数据量达TB级别。
- 利用数据压缩和冷热数据分层存储策略,降低存储成本并提高查询效率。
- 面临的挑战包括数据源的动态变化和存储规模扩展,可通过微服务化和云原生技术(如Kubernetes)实现弹性伸缩。
结语
数据处理与存储服务是舆情分析系统架构中的核心支撑,其设计需平衡性能、成本与可维护性。随着人工智能和边缘计算的发展,未来舆情系统将更注重实时智能处理与分布式存储的深度融合,为舆情监测提供更强大的技术保障。