随着人工智能技术迈入以大模型为核心的新阶段,数据处理与存储服务已从幕后支持角色,演变为决定AI大模型研发效能、成本控制与最终性能的关键基石与核心引擎。本报告旨在全面剖析2024年全球范围内,服务于AI大模型全栈技术的数据处理及存储服务的最新发展趋势、核心技术挑战与未来演进方向。
一、 数据处理:从“原料”到“高精度燃料”的进化
AI大模型的训练与迭代依赖于海量、高质量、多模态的数据。2024年,数据处理服务呈现出以下核心特征:
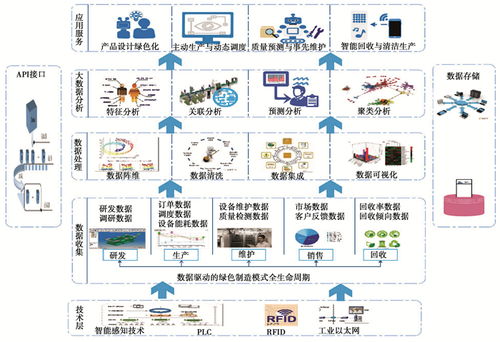
- 规模化与自动化数据流水线:面对万亿级Token的数据需求,自动化数据采集、清洗、去重、标注与质量评估流水线成为标配。企业愈发依赖集成了智能过滤、合成数据生成与毒性内容识别的一体化平台,以提升数据准备效率并保障数据安全合规。
- 多模态数据融合处理:文本、图像、音频、视频及结构化数据的对齐与联合表征是训练下一代多模态大模型的关键。数据处理服务正突破单一模态限制,发展出能理解并关联跨模态信息的统一处理框架与工具链。
- 数据隐私与合规驱动创新:全球数据法规日趋严格,催生了隐私计算(如联邦学习、差分隐私、安全多方计算)在数据处理环节的深度集成。在保护原始数据不泄露的前提下完成模型训练,已成为数据处理服务的核心竞争力之一。
- 合成数据与数据增强:为解决高质量真实数据稀缺、成本高昂及长尾问题,利用生成式AI本身创造逼真、多样且标注准确的合成数据,已成为重要的技术路径。数据处理服务正将合成数据生成、有效性验证与真实数据无缝融合。
二、 数据存储:面向大模型的性能、效率与成本最优解
大模型工作负载对存储系统的吞吐量、延迟、扩展性与成本提出了前所未有的要求。2024年的存储服务演进聚焦于:
- 分级存储与智能数据生命周期管理:根据数据的热度(频繁访问的训练数据、检查点、冷备模型等),自动在超高速NVMe存储、高性能对象存储、低成本归档存储之间迁移数据,实现性能与成本的最佳平衡。
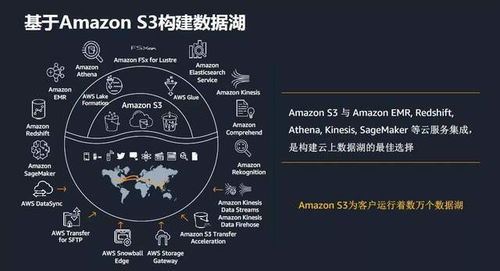
- 高性能并行文件系统与对象存储的融合:为满足千卡乃至万卡集群同时读取海量小文件(如训练样本)的需求,支持POSIX接口的高性能并行文件系统(如Lustre, GPFS)与具备极致扩展性的对象存储(兼容S3)正通过缓存、分层等技术深度融合,提供高吞吐、低延迟的统一数据湖视图。
- 存算分离架构的普及与优化:将海量数据存储在独立的、可无限扩展的存储池中,计算集群按需弹性挂载,已成为主流架构。2024年的重点在于优化该架构下的网络性能(如采用RDMA)、减少数据加载的等待时间,并确保 checkpoint 保存与恢复的高效可靠。
- 向量数据库的崛起:为大模型的检索增强生成(RAG)应用提供支撑,专门用于高效存储、索引和检索高维向量数据(嵌入)的向量数据库成为技术栈中的重要组件。其与大数据生态和传统数据库的集成能力备受关注。
三、 核心挑战与未来展望
尽管技术进步显著,行业仍面临挑战:数据质量评估的标准化、多源异构数据的治理、存储系统的能耗控制、跨云/边缘环境的数据流动性等。
数据处理与存储服务将朝着更智能化、一体化、绿色化的方向发展:
- AI原生的数据管理:AI将深度参与数据管理的全流程,实现自适应的数据发现、质量修复与存储策略优化。
- 全栈垂直整合:从芯片(DPU)、网络到软件栈的协同设计,提供端到端优化的大模型数据解决方案。
- 可持续发展:通过数据压缩、去重、高效编码以及利用再生能源的存储设施,降低大模型全生命周期的数据碳足迹。
结论
在2024年及可预见的数据处理与存储已不再是AI大模型的简单“后勤部门”,而是直接赋能模型创新、影响研发节奏、决定商业可行性的战略环节。构建敏捷、高效、安全且经济的数据基础架构,是任何希望在AI大模型浪潮中保持竞争力的组织所必须夯实的基石。