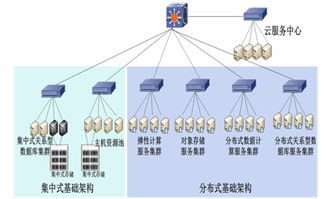
随着智能电网建设的不断深化,电力系统正经历着从自动化到智能化的深刻变革。在这一进程中,配电系统作为连接电网与用户的关键环节,其运行状态的精准分析与高效管理至关重要。全业务统一数据中心的提出,为整合分散的配电业务数据、挖掘数据价值提供了核心平台。本文旨在探讨基于该数据中心的配电分析应用中,数据处理及存储服务的关键技术与实现路径。
一、 数据处理服务的核心架构与流程
配电分析涉及海量、多源、异构的数据,包括SCADA实时数据、用电信息采集数据、设备台账数据、地理信息数据、气象数据以及用户行为数据等。数据处理服务作为连接原始数据与上层分析应用的桥梁,其核心任务在于实现数据的“提质”与“赋能”。
- 数据接入与集成:构建统一的数据总线或接入平台,支持多种协议(如IEC 61850、104规约、MQTT等)和接口,实现配电终端、计量装置、运维系统等各类数据源的实时、准实时及批量数据的可靠接入。通过数据清洗、格式标准化、冗余消除等手段,形成规范一致的原始数据池。
- 数据加工与治理:在原始数据基础上,建立数据质量稽核规则,对数据的完整性、准确性、一致性和时效性进行监控与修复。通过关联、融合、计算(如线损计算、负荷预测特征提取、设备状态指标计算等),生成面向不同分析主题(如供电可靠性分析、线损精益化管理、配网故障研判、负荷预测与优化)的高价值衍生数据资产。建立统一的数据模型与资产目录,实现数据的可发现、可理解与可信任。
- 数据服务化:将处理后的数据封装成标准化的API服务或消息流,以松耦合的方式提供给上层的配电运行分析、规划仿真、故障诊断、智能运维等应用。这包括实时数据推送服务、历史数据查询服务、专题分析数据服务等,支撑应用的敏捷开发与灵活调用。
二、 存储服务的分层设计与技术选型
面对配电数据体量大、类型杂、价值密度不一、访问模式多样的特点,存储服务需采用分层、分域的混合架构,以实现成本、性能与扩展性的最佳平衡。
- 实时/时序数据存储层:针对SCADA遥测、PMU等高频采集的时序数据,采用专用的时序数据库(如InfluxDB、TDengine或基于HBase的时序方案)。这类数据库在数据压缩、高速写入、时间范围查询方面具有显著优势,能够高效支撑实时监控、趋势分析等场景。
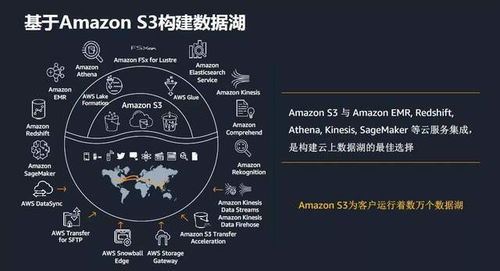
- 海量历史与明细数据存储层:对于用电信息、事件记录等海量明细数据,采用分布式大数据存储框架,如Hadoop HDFS结合Hive/Spark,或云原生对象存储服务。此层提供高可靠、低成本的海量数据存储能力,支撑长期历史数据回溯、批量离线分析与数据挖掘任务。
- 关系型与分析型数据存储层:用于存储经过加工治理后的高质量数据资产、模型参数、知识库及业务元数据。可选用高性能关系型数据库(如分布式MySQL集群、PostgreSQL)或MPP分析型数据库(如ClickHouse、Greenplum),以满足复杂关联查询、多维分析和报表生成的快速响应需求。
- 内存与缓存层:利用Redis、Memcached或内存计算框架(如Spark),缓存热点数据、中间计算结果和实时分析状态,极大提升高频访问和数据预处理的速度,为实时分析决策提供瞬时响应能力。
三、 数据处理与存储的协同与挑战
数据处理与存储服务并非孤立存在,而是紧密协同。流处理框架(如Flink、Spark Streaming)可从实时存储中消费数据,进行在线处理并写回存储或直接推送至应用;批量处理任务则定期从海量存储中提取数据,加工后存入分析型存储。面临的挑战包括:
- 数据安全与隐私保护:需建立贯穿数据全生命周期的安全防护体系,特别是用户用电数据等敏感信息。
- 资源弹性与成本控制:云化部署与容器化技术有助于实现计算与存储资源的弹性伸缩,优化总体拥有成本。
- 技术架构的持续演进:随着边缘计算、人工智能技术的融合,需考虑在边缘侧进行初步数据处理,并与中心形成云边协同的架构。
结论:在全业务统一数据中心的支撑下,构建一个高效、可靠、可扩展的数据处理与存储服务体系,是释放配电数据潜能、驱动配电分析应用智能化升级的基石。通过分层存储、流批一体处理、数据服务化等关键技术实践,能够有效应对数据洪流,为配电系统的安全、经济、高效运行提供坚实的数据内核,最终推动配电网向主动自愈、互动优化、绿色高效的智慧配电网演进。