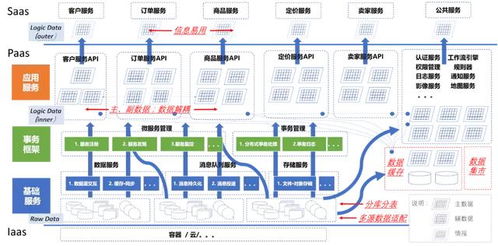
在微服务架构中,数据架构设计是确保系统可扩展性、一致性和灵活性的关键。传统单体应用通常采用集中式数据库,而微服务则倡导数据去中心化,每个服务管理自己的数据,通过API进行交互。以下是微服务数据架构设计的核心要点、数据处理及存储服务的具体实践。
一、微服务数据架构的核心原则
1. 数据所有权与去中心化
每个微服务应拥有其专属的数据库(或数据存储),确保数据模型与业务逻辑紧密耦合。这避免了服务间的直接数据库访问,减少了耦合度。例如,订单服务管理订单表,用户服务管理用户表,两者通过服务调用(如REST或gRPC)交换数据,而非直接查询对方数据库。
2. 数据一致性策略
微服务中数据一致性是一大挑战。常见方案包括:
- 最终一致性:通过事件驱动架构(如消息队列)实现异步数据同步,例如使用Apache Kafka或RabbitMQ发布领域事件,其他服务订阅并更新自身数据。
- Saga模式:用于跨服务事务,将长事务分解为多个本地事务,通过补偿机制处理失败情况。
- CQRS(命令查询职责分离):分离读写操作,写操作通过事件更新数据,读操作可使用优化后的查询存储(如缓存或只读副本),提升性能。
3. 数据隔离与安全性
每个服务的数据库应独立部署,避免单点故障。通过API网关控制数据访问权限,确保服务间通信安全(如使用OAuth2.0认证)。
二、数据处理服务的实践
1. 事件驱动数据处理
微服务常通过事件处理实现数据流转。例如,当用户服务新增用户时,发布“UserCreated”事件;通知服务订阅该事件,发送欢迎邮件。这种方式解耦了服务,提高了系统的响应性和可扩展性。
2. 流式数据处理
对于实时数据场景(如日志分析、监控),可使用流处理框架(如Apache Flink或Spark Streaming)。例如,订单服务将交易数据流式发送到处理管道,实时计算销售额指标。
3. 批处理与ETL
定期批量处理数据,用于报表或数据仓库。可使用工具(如Apache Airflow)调度ETL任务,从各微服务提取数据,转换后加载到中央数据湖(如Hadoop或云存储)。
三、数据存储服务的选型与设计
1. 多模型数据存储
根据数据特性选择存储技术:
- 关系型数据库(如MySQL、PostgreSQL):适用于需要ACID事务和复杂查询的服务,如支付服务。
- NoSQL数据库:如MongoDB(文档型,适合灵活模式)、Redis(键值型,适合缓存)、Cassandra(列存储,适合海量数据)。例如,产品目录服务可使用MongoDB存储动态属性。
- 搜索引擎(如Elasticsearch):用于全文检索场景,如电商的商品搜索服务。
2. 数据缓存策略
使用缓存(如Redis或Memcached)减轻数据库压力。常见模式包括:
- 旁路缓存:服务先查询缓存,未命中则从数据库加载并更新缓存。
- 写穿透缓存:数据写入时同步更新缓存和数据库。
3. 数据备份与迁移
每个服务应独立处理数据备份和迁移。例如,通过数据库迁移工具(如Flyway或Liquibase)管理版本化脚本,确保数据模式变更可追溯。
四、挑战与应对
- 数据重复与一致性:通过事件溯源和CDC(变更数据捕获)工具(如Debezium)监听数据库日志,同步数据变更。
- 跨服务查询:使用API组合或数据视图服务聚合多个服务的数据,避免分布式查询的复杂性。
- 监控与治理:实施集中式日志和指标收集(如Prometheus+Grafana),监控各服务的数据性能和健康状态。
微服务数据架构设计需平衡去中心化与一致性,灵活选用数据处理和存储技术。通过事件驱动、多模型存储和缓存策略,可构建高可用、可扩展的数据生态系统,支撑业务快速迭代。