实验1 数据获取、存储与预处理——从网页爬虫到数据服务的完整通路
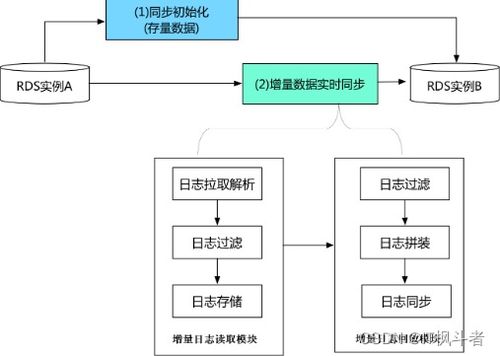
实验1:数据获取、存储与预处理\n\n## 摘要\n本实验围绕网络数据的全生命周期处理,通过一个实用案例,说明了网页爬虫构建、数据解析、数据库存储以及基础预处理的方法。实验旨在掌握自动化获取公开网络数据、结构化信息提取、数据持久化存储及脏数据清洗等关键技术和思想。\n\n## 一、实验目的\n1. 熟悉Python中的Urllib/Requests库及Scrapy框架构建简单的网页爬虫;\n2. 掌握正规表达式与BeautifulSoup进行数据解析的工具;\n3. 能够连接MySQL或SQLite数据库存储结构化数据;\n4. 配合Pandas完成基本数据预处理(缺失值移除、去重、文本规整),建立一条清洗到服务的概览流程。\n\n## 二、技术路线\n使用开源数据集网络(如GitHub开源列表、天气查询或蘑菇分类样例站),基本设计如下:\n
如若转载,请注明出处:http://www.bangwospp.com/product/85.html
更新时间:2026-06-18 18:29:55